

Le reti neurali artificiali (ANN) sono modelli matematico-informatici ispirati al modello delle reti neurali biologiche, capaci di apprendere sfruttando meccanismi simili a quelli dell’intelligenza umana e degli animali più evoluti.
Diversamente dalla programmazione “convenzionale”, in cui una macchina informatica esegue un compito suddividendo un problema in compiti più piccoli e facilmente eseguibili, una rete neurale impara dai dati osservativi in una logica di “autoapprendimento”, individuando la propria soluzione al problema. Ecco perché si parla di Intelligenza Artificiale quando un sistema si basa su circuiti neurali artificiali.
Le ANN possono essere utilizzate per simulare relazioni complesse tra ingressi e uscite che altre funzioni analitiche non riescono a rappresentare.
Per comprenderne, dunque, il funzionamento pensiamo alle reti neurali del nostro cervello: esse sono formate da una fitta rete di cellule nervose interconnesse tra loro che elaborano ciò che avviene nell’ambiente circostante, fornendo risposte adattive sulle esigenze che si presentano. Una rete neurale biologica riceve dati e segnali esterni (attraverso gli organi di senso) che vengono elaborati in informazioni attraverso un enorme numero di neuroni interconnessi in una struttura non-lineare e variabile a seconda degli stimoli esterni ricevuti.
Per le reti neurali artificiali funziona pressoché allo stesso modo: esse ricevono segnali esterni su uno strato di nodi (detti “nodi d’ingresso”) i quali sono collegati a svariati nodi interni della rete e organizzati a più livelli in modo che ogni singolo nodo possa elaborare i segnali ricevuti, trasmettendo ai livelli successivi i risultati elaborati.
Le performance delle reti neurali dipendono dal processo di “addestramento” mediante apprendimento automatico.
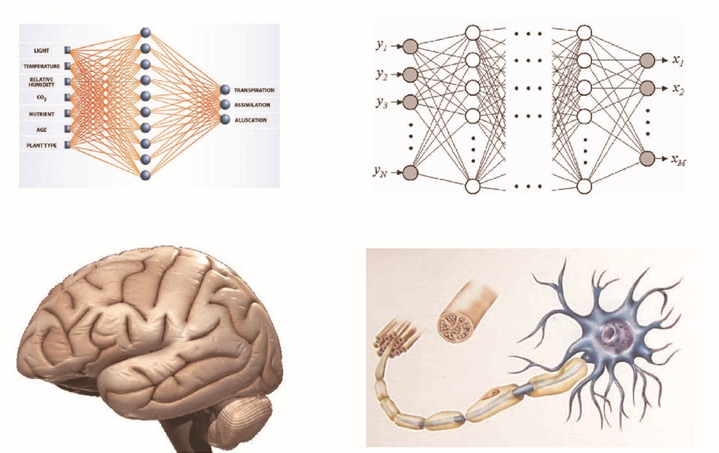
Se il primo modello basato su neuroni artificiali, proposto da McCulloch e Pitts nel 1943, in grado di eseguire solo funzioni booleane elementari, aveva però scarsa precisione e, quindi, era poco adatto a svolgere operazioni più complesse, Rosenblatt nel 1958 elaborò la prima rete neurale, creando le basi dell’apprendimento automatico con Perceptron (modello feed-forward).
I successivi perfezionamenti di questo modello di apprendimento: Perceptron multistrato (Werbos,1974) ed Error Back-Propagation (Rumelhart, Hinton e Williams nel 1986) insieme ad altri numerosi studi, hanno permesso al machine learning di trovare campi di applicazione pratica.
Come apprendono le reti neurali artificiali
Gli algoritmi di apprendimento delle reti neurali possono essere suddivisi in tre categorie:
- Apprendimento supervisionato: la rete analizza un training set (cioè un insieme di input ai quali corrispondono output noti) e apprende come calcolare nuove regole di associazione input-output, processando input esterni al training set;
- Apprendimento non supervisionato: la rete riceve solo un insieme di variabili di input ed elabora dei cluster rappresentativi per categorizzarle;
- Apprendimento per rinforzo: la rete apprende esclusivamente dall’interazione con l’ambiente, attraverso un circuito di incentivi e disincentivi per ottenere il risultato sperato.
Non esiste un metodo di apprendimento migliore di un altro, ma la scelta dipende dalla tipologia di dati a disposizione e dai risultati che si vogliono ottenere.
Da questo punto di vista è molto importante la preparazione e l’esperienza dell’operatore che implementa modello.
















































































































{kind=link}